



こうした中、コナミデジタルエンタテインメントで人気ゲーム『ドラゴンコレクション』のマネージャーを務める廣田竜平氏は、「大人気ソーシャルゲームを支える技術 〜拡大し続けるシステムの軌跡」と題して、その一端をあきらかにしました。2011年11月で550万人のユーザーを抱えるヒットタイトルの基盤技術だけあって、講演終了後もさまざまな質問が飛び出す人気セッションとなりました。
 |
| コナミデジタルエンタテインメント ドラコレスタジオ マネージャー 廣田竜平 氏 |
廣田氏は新卒でKONAMIに入社後、『ドラムマニア』『クイズマジックアカデミー』シリーズなど、アミューズメント機器の開発にプログラマーとして携わってきた経歴の持ち主です。その後MMORPGやiPhoneアプリなどの開発を統括。『ドラゴンコレクション』では技術面の責任者として、アプリとインフラの双方から方針決定や課題解決を担当してきました。
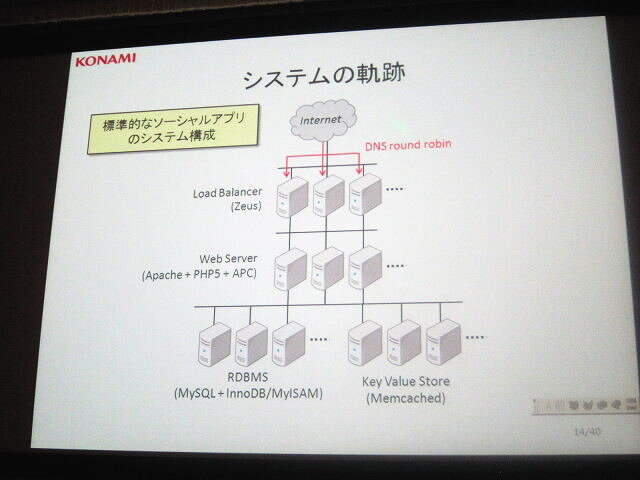
まず廣田氏は「開発環境は一般的なLAMP環境です」と切り出しました。LAMPとはLinux(OS)、Apache HTTP Server(Webサーバ)、MySQL(データベース)、Perl、PHP、Python(スクリプト言語)の頭文字のこと。このうちOSはCentOS 5、WebサーバはApache 2、言語はPHPがメインとなっています。KVS(Key-Valueストア)はmemcashedベースで、一部membasedを使用するケースもあるとのこと。つまり「大規模タイトルといっても、特別なことはしていませんよ」というわけです。
 |  | 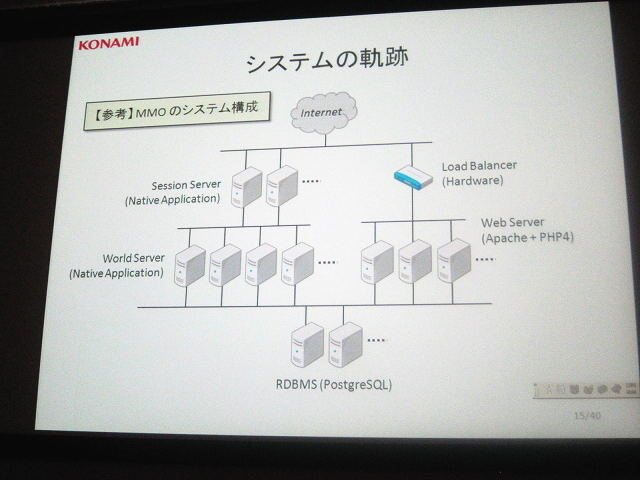 |
| 開発環境は一般的なLAMP環境 | 一般的なソーシャルゲームのシステム環境 | 自社MMORPG環境ではネイティブ環境も見られた |
システム構成についても、一般的なソーシャルアプリと同じとのこと。インターネットからのアクセスに対して負荷分散を行い、その下にウェブサーバが連なり、最後にデータベースサーバやキャッシュサーバが連なる構成です。MMORPGの開発・運用ではネイティブアプリでセッションサーバ・ワールドサーバ・ウェブサーバが構築されていたこともありましたが、現在はすべてこの方式に統一されています。
もっとも、規模については指数関数的に上昇していきました。廣田氏は社内テストで評判だったこともあり、「かなり手厚いサーバ構成で始めた」と述べました。ところが蓋を開けてみると、事態はとんでもないことに。当初は「嬉しい悲鳴」だったはずが、ただの「悲鳴」に変わるのに、長い時間はかかりませんでした。リリース後8ヶ月くらいまで拡張に次ぐ拡張が行われ、特にアクティブユーザー数が数万から数十万人に増えていった頃が、もっともきつかったそうです。
 |  |
| 短期間に | 拡張が続いた |
 |  |
| 『ドラコレ』の | 足回り |
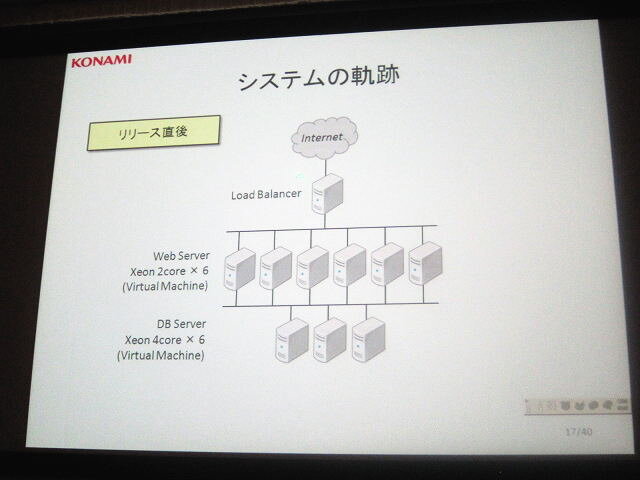
■リリース直後
ロードバランサー *1
仮想ウェブサーバ(Xeon 2 core)*6
仮想データベースサーバ(Xeon 4 core)*6
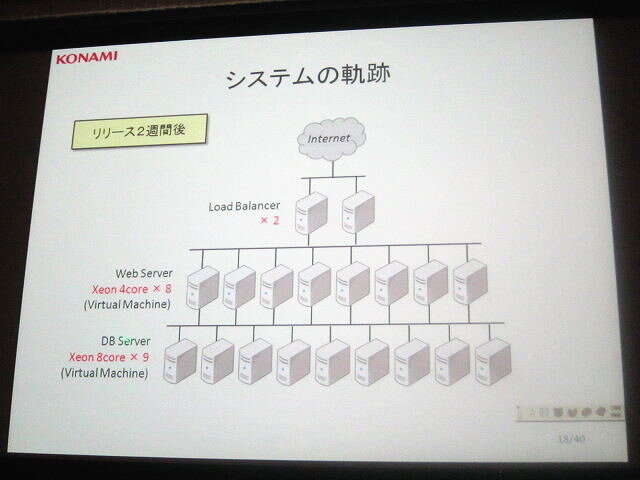
■2週間後
ロードバランサー *2
仮想ウェブサーバ(Xeon 4 core)*8
仮想データベースサーバ(Xeon 8 core)*9
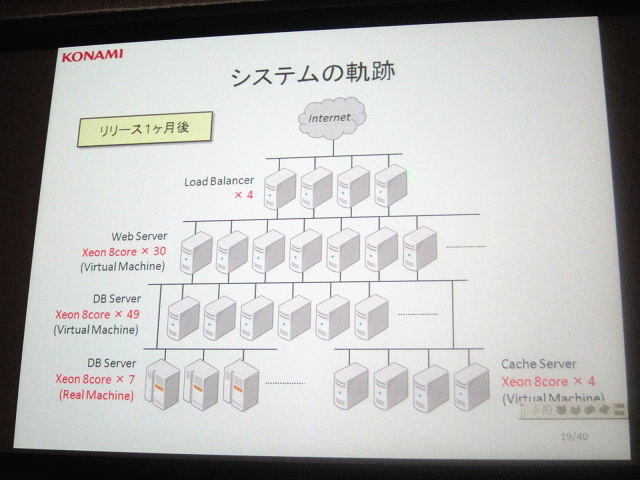
■1ヶ月後
ロードバランサー *4
仮想ウェブサーバ(Xeon 8 core)*30
仮想データベースサーバ(Xeon 8 core)*49
データベースサーバ(Xeon 8 core)*7
仮想キャッシュサーバ(Xeon 8 core)*4
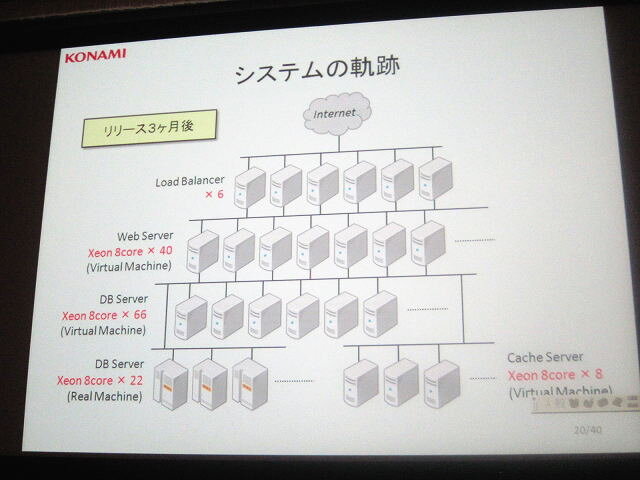
■3ヶ月後
ロードバランサー *6
仮想ウェブサーバ(Xeon 8 core)*40
仮想データベースサーバ(Xeon 8 core)*66
データベースサーバ(Xeon 8 core)*22
仮想キャッシュサーバ(Xeon 8 core)*8
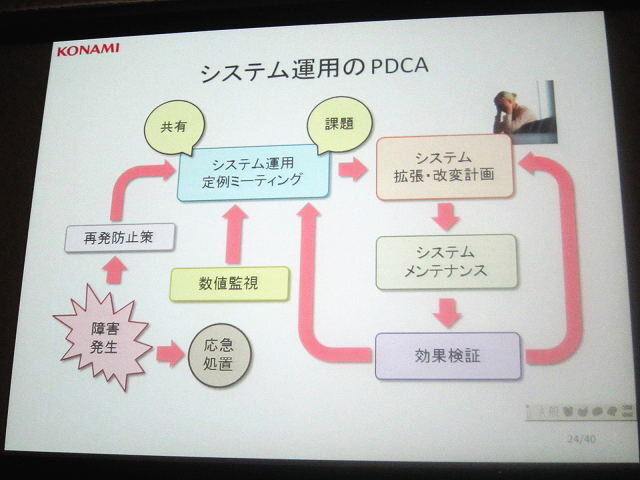
一方で廣田氏は「システムとはインフラとアプリの両方があわさった概念」だと説明します。その上で重要なのはPDCA(計画・実行・評価・改善)のサイクルを回しながら、運用実績を積み上げていくこと。さらに具体的な障害が発生するまえに、数値監視などを通して障害を未然に防ぐ体制づくりが求められると言います。
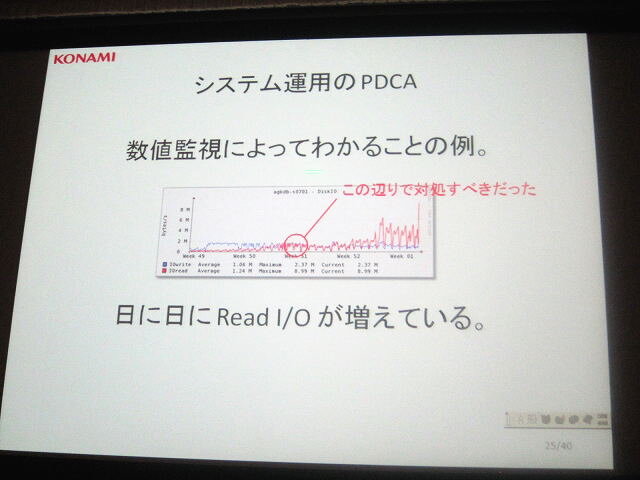
「障害はある一点を超えると一気に拡大します。そのため兆候を見逃さないことが重要です」(廣田氏)。講演ではサーバのアクセスに対する書き込み/読み込み頻度のグラフが紹介されました。書き込み頻度に対して読み込み頻度が徐々に増加し、両者が同じくらいになっています。本来はここで対処すべきでしたが、放置した結果、一気に読み込み頻度が増加し、障害に繋がってしまいました。
 |  |  |
| PDCAサイクルでシステムを運用 | 兆候を見逃すと大惨事になる | 障害後の対策は心身ともに疲弊する |
こうしたことが発生するたびに、深夜でもおかまいなしに携帯メールが鳴り、対処が求められるのだそうです。ちなみに『ドラコレ』では当初サーバ側のプログラマは2名でスタートしましたが、すぐに人手不足になり、増強されたそうです。残念ながら具体的な人数は明かされませんでしたが、それなりの体勢であることが想像できます。
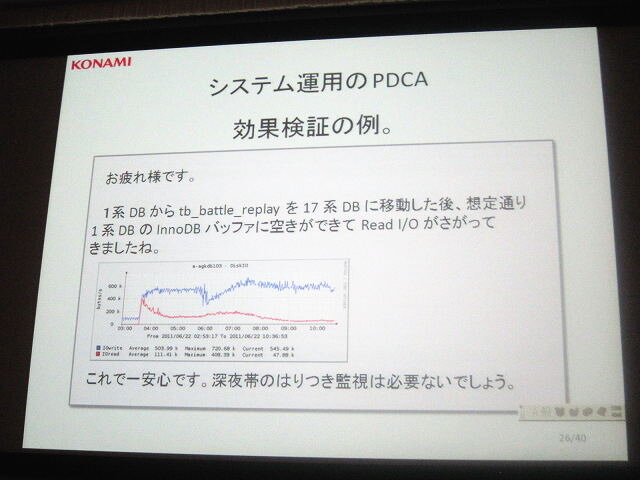
また規模が大きくなるにつれて、Inno DBのバッファプールサイズとの戦いも新たな問題となりました。まるっとまとめると、会員の増加につれて会員データベースのサイズが増大化し、データベースのバッファ(一時格納領域)に入らなくなってきたのです。バッファに入らなければディスクの読み込みアクセスが増加し、障害に繋がってしまいます。さらに会員数の増加に伴いデータベースサイズは増え続けます。
 | 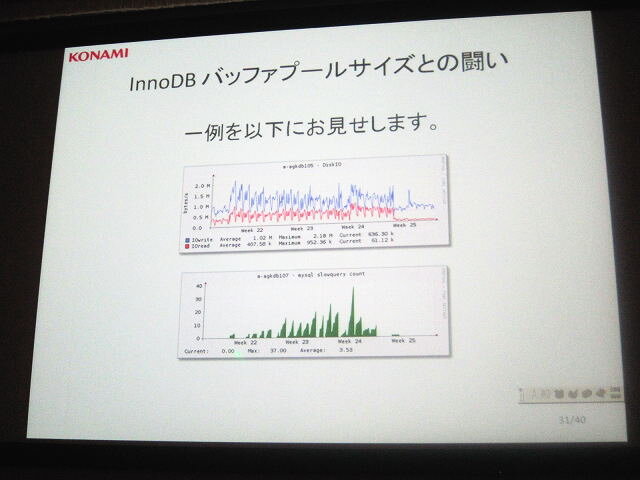 |  |
| バッファプールサイズ問題の解消も | 日常的な監視で | 対応できる |
この問題に対する解決方法はただ一つで、データ待避や分割を行って、大元のデータサイズを小さくすること。これなども障害が発生してから対応するのではなく、週単位でデータベースのサイズを比較し、急に伸びている部分を洗い出してチームで共有し、事前に対応することが重要だとされました。
このほか「いざという時の輪番アクセス」というテクニックも紹介されました。一般的にシステムが増大化すると、新機能を追加する際の負荷テストが難しくなります。そこでスケールダウンした環境で負荷テストを行い、その結果に係数をかけるなどの処理が行われますが、実際には単純計算ではわりきれない障害が発生します。そうならないように、過去の実績やパラメータ(CPU Usage、ディスクI/O、データベースサイズ、バイナリログなど)から総合的に判断されるわけですが、それでもパンクしてしまうのが事実です。
そこで当初からユーザーを複数のグループに分け、定期的に利用できる範囲を変えていく方法が考えられました(輪番停電にならって輪番アクセスと命名されました)。サービス全体に加えて、特定の機能に関しても、この方式で開放率をコントロールできるようにしておきます。これによって特定の機能障害でサービス全体が止まることを防ぐようにするわけです。「全体のアクセス数を抑えたいときに、処理を早い者勝ちにするよりも、不公平感がなくて実装が楽」だといいます。
 |  |
| 輪番アクセスで | 保険をかけることで |
 |  |
| 非常事態にも | 備えられる |
また質疑応答ではクラウドサーバとの兼ね合いが議論されました。前述のインフラ推移を見ればわかるように、『ドラコレ』も当初はクラウドサーバで行われていましたが、途中からパートナー企業のデータセンターの活用が加わり、今ではそちらを中心に運用を切り替えているそうです。ソーシャルゲームでは事前のヒット予測が難しいため、初期の拡張時にはクラウドサーバの活用が有効だが、安定期以降はより痒いところに手が届く、自社サーバやデータセンターの活用も有効ではないか、と話されていました。