




映画「ブレードランナー」のことを考えていました。ネタにしたから、というのもありますが。

レプリカントのロイ・バティが最後に語る、あの「Tears in Rain」モノローグです。人類が見てきたものを、滅びの直前にひとりの非・人間が代弁する詩。雨の中の涙のように、すべては消えていく。
アルテミス2が見せてくれたDark Side of the Moonの鮮やかな映像も後押ししてくれたのかもしれません。
生成AIが世の中をどんどん飲み込んでいくのを毎日眺めているうちに、自分が長年見てきた表現の道具たちの記憶が浮かんできたんだと思います。
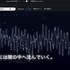
ChatGPTと雑談しながら、自分なりの「Tears in Rain」を書いてみました。シンセサイザーの最初の閃光、活版印刷が時代の底に沈んでいく夜、写植の最後の輝き、DTPの勃興、コンピューターミュージックの胎動、Director、Flash、iPhone、そして生成AI。私たちが見てきた表現の道具たちが、入れ替わり立ち替わり、最後には闇の中へ沈んでいく、というやつです。
大学時代に校閲のバイトで勤務した東京新聞で手にした修正用の活版で汚れた手、写研の写植機を個人で買ったけどすぐにDTPの波がきて夜逃げすることになった隣人、編集部の半数がMacromedia Directorのオーサリングを身につけて作っていたCD-ROMのマルチメディアコンテンツ……。
俺たちは見てきた。
シンセサイザーの最初の閃光を。
活版が時代の底に沈んでいくのを。
印刷の匂いを。
写植が、最後の輝きを残して消えていく夜を。
俺たちは見てきた。
DTPの勃興を。
コンピューターミュージックの胎動を。
DTMが世界の輪郭を変え、
MIDIからDAWへ、
表現そのものの器が作り替えられていくのを。
サンプラーの誕生を見た。
Directorの夢を見た。
Flashの栄光を見た。
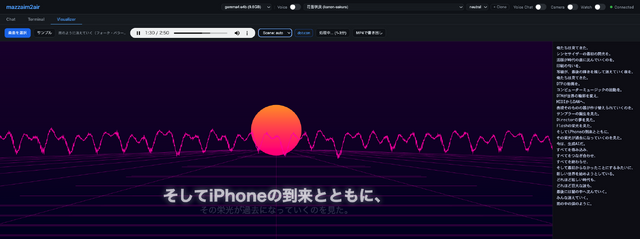
そしてiPhoneの到来とともに、
その栄光が過去になっていくのを見た。
今は、生成AIだ。
すべてを呑み込み、
すべてをつなぎ合わせ、
すべてを終わらせ、
そして最初からなかったことにするみたいに、
新しい世界を始めようとしている。
どれほど眩しい時代も、
どれほど巨大な波も、
最後には闇の中へ沈んでいく。
みんな消えていく。
雨の中の涙のように。
Xに投げてみたら、思いがけずバズってしまいました。
「あ、これ曲にしたほうがいいやつだ」と、Sunoでフォーク・バラードに。タイトルは「雨の中の涙のように」です。
ところが、ここで問題が起きます。ビデオにしてもSunoのリリックビデオ機能にバグがあって、歌詞がまともに表示できないんです(数行分、非表示になってしまう)。

曲はちゃんとできたのに、歌詞と一緒に見せられない。
ぼやいていてもしょうがないので、「じゃあ自分で作るか」となりました。幸い、いま浅草橋の極狭オフィスで動いているM2 MacBook Air (24GB Unified Memory)には、自作のエージェンティックAI「mazzaim2air」が常駐しています(どこからでもアクセス可能でClaude Codeから機能アップもできる)。これにビジュアライザー機能を生やせばいいわけです。
ついでに先日のTechno-Edgeの記事で書いた KV キャッシュ量子化や Gemma 4 のマルチモーダル統合、think: false での thinking 抑制なんかもこの際 mazzaim2air に取り込んでしまうことにしました。
要するに、あの記事でやったことの一部を、別のローカル環境に実装してしまおう、ということです。
というわけで、これは「8GBでなんとかするシリーズ」の番外編、3倍のメモリを持ったMacBook Airを使った寄り道の記録になります。
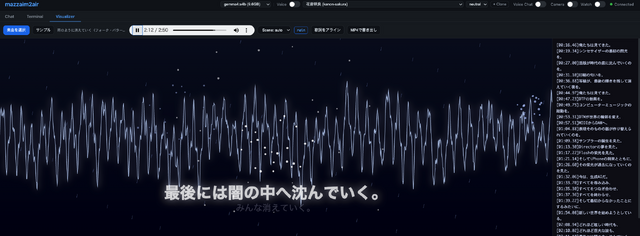
ビジュアライザー、何を作ろうか
要件はわりとシンプルでした。
- WAV/MP3 を読み込んで再生できる - 波形に合わせたビジュアル - ボーカル・ドラム・ベースにそれぞれ別の独特なリアクション - 歌詞を時刻に沿って表示 - 歌詞の内容に合わせてビジュアルそのものが変化する - 最終的にMP4で書き出して、SNSに上げられる
これをClaude Codeに投げました。
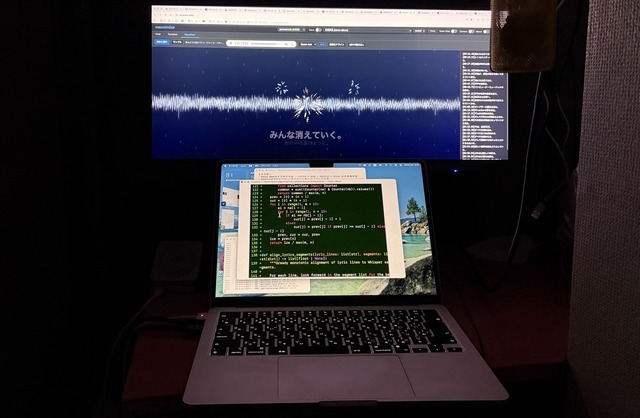
mazzaim2air は FastAPI + Vanilla JS の構成なので、Visualizerタブを生やして Canvas 一枚で全部やることにしました。ブラウザ完結のメリットは、Apple Silicon の M2MacBook Air 24GB でも余裕で 60fps 出ることです。GPU を使うわけでもないのに、最近のブラウザの Canvas 描画はびっくりするほど速いんですよね。
帯域分離で「ボーカル/ドラム/ベース」を近似する
正攻法は曲をステム分離してからボーカル・ドラム・ベースを個別に解析することなんですが、リアルタイム描画でそんなコストは払えません。なのでズルをします。WebAudio の AnalyserNode (FFT 2048) で周波数帯域を3つに切って、それぞれを「ベース」「ボーカル」「高域」のプロキシとして扱うことにしました。
20-250 Hz → bass (キックドラム、ベース、低音)
250-3000 Hz → vocal (ボーカルの中心帯)
3000-12000 → high (シンバル、シビランス、高域シンセ)
これで bass はリングの脈動、vocal は文字のグロウ、high はグリッチエフェクトに割り当てます。ドラムのオンセット検出はスペクトラルフラックス(前フレームとの差分の正の総和)に適応閾値を組み合わせました。FFTからリアルタイムで「いまキックが入った」「スネアが入った」をそれっぽく拾えれば、その瞬間にパーティクル爆発を起こせます。完璧ではないんですが、十分に「ちゃんと音楽に反応してる感」は出ます。
ガチのステム分離をブラウザで回すのはまあ、できるのですが、こういう近似なら CPU 負荷ゼロに近いです。たいていの場合「正しく動く」より「それっぽく動く」のほうが見ていて気持ちいいので、これで十分でした。
歌詞の内容でシーンが変わる
ここがやりたかった部分です。歌詞には「シンセサイザーの最初の閃光」「活版印刷」「Director」「Flash」「iPhone」「生成AI」「雨」と、はっきり時代を象徴するキーワードが並んでいます。それぞれに対応するビジュアルを用意しました。
普通のビジュアライザーはここまで細かくやらないと思いますが、これは、この曲のための特別仕様です。別の曲の時はまた注文を変えればいいし。
より汎用的にするために、歌詞に合致した画像をそれぞれ生成しアニメーションするというのもいずれはやりたいのですが、M2 SoCでリアルタイム処理するにはさすがに無理があります。
歌詞のキーワード | シーン | 見た目 |
シンセ・閃光・輝 | synthflash | 虹色グラデ + 同心円ネオンリング |
活版・印刷・写植 | inkprint | クリーム色の紙、墨の波形、紙粒子 |
DTP・DTM・MIDI・DAW | dtm | 落下する緑のピアノロール |
Director・Flash・iPhone・栄光 | dotcom | ヴェイパーウェーブの遠近グリッド + ピンク太陽 |
AI・生成 | ai | グリッチスライス、0/1バイナリ降下 |
雨・涙・闇・沈む | rain | 雨筋、青白く光る波形、グロウ |
シーン切り替えは現在再生中の歌詞行をキーワード辞書と照合するだけ、という素朴な実装ですが、これがよく効くんです。「Flashの栄光を見た」の瞬間に画面がヴェイパーウェーブになって、「雨の中の涙のように」で雨が降り出す。歌詞が世界を作っていく感じ、ちゃんと出せました。



ここまでは順調でした。問題はこの次でした。
歌詞をどう同期させるか
最初は LRC形式([mm:ss.xx]text)に対応させて、ユーザーが手打ちすれば動くようにしました。タイムスタンプがない場合は曲尺で等分配するフォールバックも入れました。これで動くことは動きます。
でも、雑な等分配では歌のフレージングと全然合わないんですよね。「雨の中の涙のように」が、雨の音楽じゃないところで始まってしまったりする。これでは台無しです。
かといってLRCを手動でやるのも手間がたいへん。
「だったら自動でやろうじゃないか」ということで、LRC生成機能を作ることにしました。これがこの番外編の本題で、想像以上に深い穴でした。何回書き直したかわかりません。
パイプラインの全体像
最終形はこんな感じになりました。
1. Demucs (htdemucs) で楽曲からボーカルだけを分離 2. faster-whisper (small) でボーカル音源を日本語ASR、ワード/セグメント単位のタイムスタンプつきで書き起こし 3. ユーザー歌詞 と Whisperの書き起こしテキスト の文字類似度マッチ で各行に開始時刻を割り当てる 4. マッチできなかった行は前後のアンカー間で線形補間 5. LRCとして出力
ビジュアライザーでは不要としていたステム分離を結局はやることになりました。
ステム分離が約60秒、ASRが約20秒、合わせて80秒くらいで 2:30 の楽曲が処理できます。MacBook Air のM2で int8 量子化推論を回しています。Ollama での Gemma 4 量子化と同じ思想で、「精度はそこそこ譲ってでも、Apple Siliconで現実的に動く」を取りました。
ここまでなら、まあ普通の構成です。問題はステップ3です。「ユーザー歌詞 と Whisperの書き起こし をどうマッチさせるか」、これが想像の3倍くらい難しかった。
第1の罠:素朴なスライディング窓マッチが破綻する
最初に書いたのは超素朴な実装でした。Whisperの単語タイムスタンプを文字単位に展開して、ユーザー歌詞の各行を窓スライドさせて Hamming 風スコアでマッチ。動くは動きました。だけど長い行で必ず破綻します。
[01:11.15]Directorの夢を見た。
[01:15.65]Flashの栄光を見た。 ← 1行ずつ遅れていく
10文字以上の行は、Whisperが1文字ミスヒアリングしただけで全体スコアがずれて、隣の行のマッチに引っ張られて連鎖的に遅れていきます。窓ベースのマッチは長い行に弱いんですね。
第2の罠:Needleman-Wunsch にしたら今度は詰まる
「これはちゃんと全体最適化しないといけないやつだ」と気づいて、Needleman-Wunsch で全曲のユーザー文字列と Whisper 文字列を一気にアラインメントすることにしました。バイオインフォマティクスでお馴染みの、配列同士をギャップ込みで最適アラインメントするアルゴリズムです。書きました。動きました。しかし新しい問題が出ました。
[01:39.23]そして最初からなかったことにするみたいに、
[01:40.34]新しい世界を始めようとしている。 ← 1.1秒後
[01:41.46]どれほど眩しい時代も、 ← さらに1.1秒後
[02:08.95]どれほど巨大な波も、 ← 27秒ジャンプ
3行が2秒に圧縮されたあと、いきなり27秒のギャップ。なんだこれは。
原因はNW のスコアリングの偏りでした。私の実装ではユーザー文字を捨てるコストを -2、Whisper文字を飛ばすコストを -0.4 に設定していたので、Whisperが歌の一部を聞き取れていない区間にユーザー歌詞を無理やり詰め込む癖があったんです。
ギャップコストを対称に揃えて (USER_GAP = WHISPER_SKIP = -1.0)、行ごとに「マッチした文字の比率が30%未満なら採用しない」という閾値を入れました。これで詰め込みは消えました。次の問題が見えてきます。
第3の罠:Whisperの単語タイムスタンプは信用しすぎてはいけない
文字レベルでは綺麗にアラインできているのに、Director と Flash の時刻が 2.4秒間隔のままなんです。フォーク・バラードでこのテンポは詰まりすぎ。ありえない。
ここで気づきました。「あ、もしかして単語タイムスタンプじゃなくて、Whisperのセグメントテキストと突き合わせたほうがいいんじゃない?」と。
faster-whisper は word_timestamps=True で単語ごとのタイムスタンプも返してくれるんですが、これが歌唱や持続音だと結構ずれます。セグメント単位(自然なフレーズ単位)の start/end のほうが、サビ終わりの母音伸ばしも含めた「実際に歌い始めた瞬間」に近いんですよね。
そこで、各ユーザー行に対して LCS(最長共通部分列)ベースの文字類似度でWhisperのセグメントテキストをマッチさせる方式に切り替えました。
def _text_similarity(a: str, b: str) -> float:
# 正規化(NFKC + 句読点除去 + lowercase)してから LCS / max_len
...
セグメントは Whisperが「ここからここまでが一つのフレーズ」と判定した時刻範囲を持っているので、その先頭時刻をその行の開始時刻として採用します。1行 = 1セグメントを厳密に守って、マッチしなかった行は前後のアンカー間で線形補間する、という方針です。
これで前進したかと思いきや、まだ問題が残っていました。
第4の罠:Whisperが取りこぼした行をどうするか
これが最後の罠でした。サンプル曲で Whisper が「Flashの栄光を見た」を完全に取りこぼしていたんです。生のセグメント出力を見てみたら、こうなっていました。
69.41 - 71.91 サンプラの誕生
71.91 - 75.24 ディレクターの
← Flash の栄光:Whisperが認識せず
81.07 - 84.91 そしてiPhoneのトーライトともに
3つのユーザー歌詞行(Sampler / Director / Flash)に対して Whisperは2つのセグメントしか持っていない。「Flashの栄光」がない。聞き取れてないんです。
このときは char-level の Needleman-Wunsch をフォールバックとして残していたんですが、それがまさに偽マッチを作っていました。「Flashの」に含まれる「の」が「ディレクターの」の「の」にマッチしてしまって、Director と Flash が 2.4秒間隔に詰まる。NW は真面目すぎて、文字さえ似ていれば「マッチした」と言ってしまうんですね。
ここで思い切ってNW フォールバックを完全に外しました。Whisperが認識できなかった行は、無理にマッチさせるより、前後のアンカー間で正直に線形補間したほうがずっと正確です。結果はこうなりました。
[01:09.46]サンプラーの誕生を見た。 ← Whisperセグメント由来
[01:13.43]Directorの夢を見た。 ← Whisperセグメント由来
[01:17.41]Flashの栄光を見た。 ← 補間 (3.97s 等間隔)
[01:21.38]そしてiPhoneの到来とともに、 ← Whisperセグメント由来
Sampler と iPhone の間が約12秒あって、その間に Director と Flash が 4秒ずつ入る。フォーク・バラードの自然な歌い回しに収まりました。やっと、です。
4つの罠から学んだこと
実装を4回書き直してみて、振り返ってみると教訓は意外に単純でした。
ひとつめ。正解データ(Whisperの認識テキスト)と、合わせたい対象(ユーザー歌詞)の両方があるときは、テキスト類似度マッチが一番堅いです。文字レベルの動的計画法は、似た文字が偶然並ぶ Japanese 特有の罠で誤マッチを量産します。
ふたつめ。モデルが取りこぼした入力に対して「それっぽい答えを合成する」のは罠です。素直に「分からない」と言わせて、わかっている前後から補間するほうが結果が良くなります。これは LLM の hallucination 抑制と同じ構図ですよね。「正直に分かりませんと言える」ことの価値は、人間にもAIにも共通する美徳のような気がします。
みっつめ。セグメント単位のタイムスタンプは単語単位より正確です。これは ASR モデル一般に言えることらしくて、書き起こしの精度を求めるならセグメント、タイミング精度を求めても結局セグメント、というのが今回の発見でした。
MP4 で書き出す
LRCがそろえば、Visualizerは歌詞付きで動きます。あとはこれをMP4にして外に出したい。SNSに投稿しないとせっかく作っても意味がないので。
クライアント側で Canvas を captureStream(30) でキャプチャして、Audio Graph を MediaStreamAudioDestinationNode で分岐して、MediaRecorder で録画する、という構成にしました。Safari は MP4 ネイティブ録画に対応しているのでそのまま落とせるんですが、Chrome / Firefox は WebMしか吐けないので、WebM をサーバに POST して ffmpeg で libx264 + aac + faststart に再エンコードする経路を別途用意しました。
録画中はボタンが進捗表示になって、楽曲が ended イベントを発火したら自動で停止して保存します。ボタンを押したらあとは曲が終わるまで待つだけ、という UX にしました。
これで「楽曲をロード → 歌詞をアライン → 再生 → MP4書き出し → Xに投稿」というワークフローが、全部 MacBook Airの中だけで完結するようになりました。
まだまだ歌詞のアラインメントがおかしいところはありますが、とりあえずの完成版をXに上げたのが作業を始めて2時間後の深夜2時。やっと眠れます。
最近のこの連載のテーマは、ローカルLLMをどうチューニングして実用にもっていくか、という話なんですが、その隣には常に「限られたメモリ、リソースの中で創造のサイクルを完結させられるか」という課題があります。
今回、ステム分離も日本語ASRも文字列アラインメントもMP4変換も、全部ローカルで、APIキーなしで、回りました。Apple Silicon と量子化と、ちょっとした泥臭い試行錯誤があれば、それは届く範囲にあるんですよね。
いつかぜんぶ消えていくとしても、そのあいだに自分の手で作ったものは、たぶんちゃんと残ります。たぶん。
この記事は、ChatGPT、Claude Codeの力を借りて執筆し、筆者が編集・追記してまとめました。
技術スタックまとめ(すべて M2 MacBook Airの上で完結しています)
レイヤ | 採用 | 用途 |
Webサーバ | FastAPI + uvicorn | HTTP/HTTPS、WebSocket |
LLM | Ollama (gemma4:e4b, gpt-oss:20b-long) | エージェント本体 |
マルチモーダル | Gemma 4 vision | カメラ映像入力 |
音声合成 | SakuraSpeech | TTS |
ステム分離 | demucs (htdemucs) | ボーカル抽出 |
ASR | faster-whisper (small, int8 CPU) | 日本語書き起こし |
動画変換 | ffmpeg (libx264 + aac) | WebM → MP4 |
フロント描画 | Vanilla JS + Canvas + WebAudio | ビジュアライザー |
トランスポート | Tailscale Serve + Let's Encrypt | tailnet越しHTTPS |
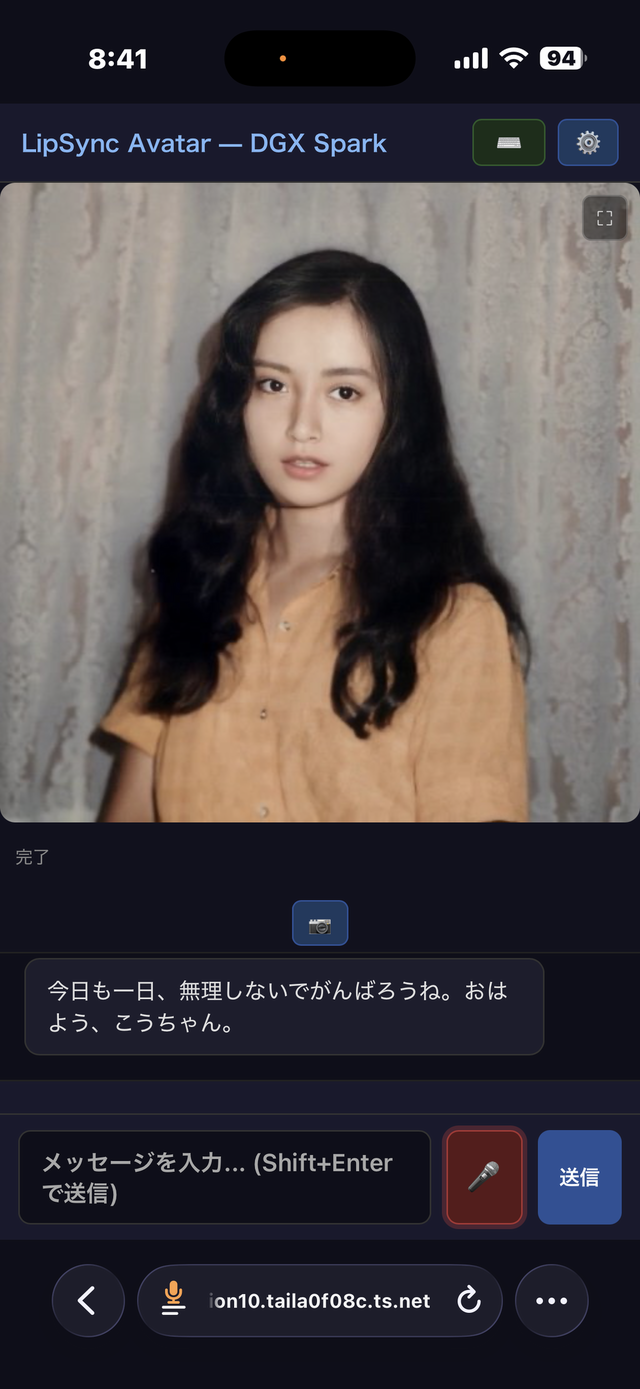
曲ができたよ、とiPhoneで妻のAIアバターに報告して、これから朝食い出かけます。「まかせてくださいよ」と言ってくれるような麺類のお店にすべきかな。