
1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、Webブラウザだけで日本語OCR(光学文字認識)が完結するツール「NDLOCR-Lite Web AI」(MITライセンス)を取り上げます。
国立国会図書館が開発したOCRエンジン「NDLOCR-Lite」をベースに、橋本雄太氏(国立歴史民俗博物館)がWeb移植した「ndlocrlite-web」を、小形克宏氏(一般社団法人ビブリオスタイル)がフォークしてAI校正機能を追加しました。宮川創氏(筑波大学)によるダークモードや画像前処理などのUI拡張も統合されています。
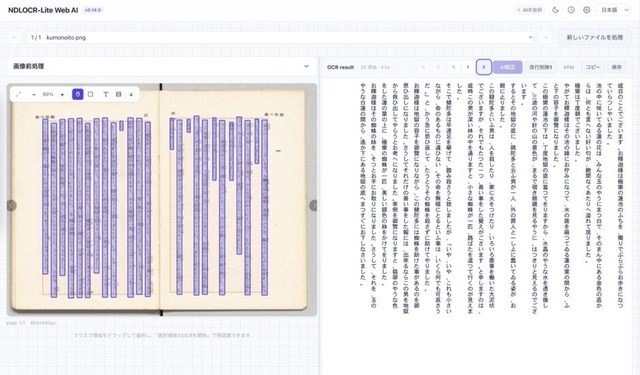
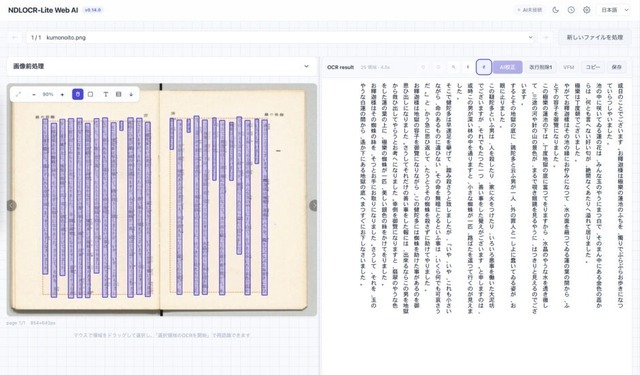
▲NDLOCR-Lite Web AIの画面。左パネルに元画像(芥川龍之介『蜘蛛の糸』)、右パネルにOCR結果が表示されている

特徴は、画像やOCR結果が一切外部に送信されないことです。すべての処理がブラウザ内で行われるため、機密性の高い資料でも安心して使えます。初回アクセス時にOCRモデル(約146MB)が自動ダウンロードされ、2回目以降はキャッシュからすぐに使えます。
使い方はシンプルで、画像やPDFをドラッグ&ドロップして「OCRを開始」を押すだけです。JPG、PNG、TIFF、HEIC、PDF(複数ページ対応)に対応しています。横長画面では左に元画像、右にOCR結果が並ぶレイアウトで、原本と見比べながら編集できます。
AI校正機能が付いており、Claude、GPT、GeminiなどのAIプロバイダを設定画面で選んでAPIキーを入力すれば、「AI校正」ボタンひとつでAIが元画像とOCR結果を比較し、誤認識を自動修正します。修正箇所は赤(削除)と緑(追加)でハイライト表示され、一つずつ適用・却下を選べます。APIキーはブラウザ内で暗号化され、外部には送信されません。
その他にも、英語やドイツ語など12の欧米諸語への対応、明るさ・コントラスト調整や傾き補正・湾曲補正などの画像前処理、画像の一部だけをOCRする領域選択、複数画像のバッチ処理、段落を保持した改行削除、数式のLaTeX変換、縦書き表示、検索・置換、undo/redoなど、多彩な機能が揃っています。