1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、大規模言語モデル(LLM)が低品質なウェブテキストに継続的に晒されることで、認知機能の低下を引き起こすことを明らかにした論文「LLMs Can Get “Brain Rot”!」を取り上げます。米テキサスA&M大学などに所属する研究者らが発表しました。
オックスフォード大学出版局は、2024年の「Word of the Year」(今年の言葉)として「Brain Rot」(脳の腐敗)を選定しました。「Brain Rot」とは、インターネット上の低質なコンテンツ(SNSの短い動画や質の低いネット情報)に依存したように大量消費することによる認知機能の低下を指します。

▲Xの人気だが低俗な投稿を見続けるとAIも性能が低下(人間のように脳が腐敗)するイラスト(絵:おね)
研究チームは、人間に起きるこの現象がLLMにも当てはまるのではないかと考え、検証を行いました。検証のため、実際のXの投稿データを用いて、ジャンクデータと通常データの影響を比較しました。ジャンクデータの定義は次の2つです。
いいねや引用、返信などが多く、ユーザーをより長くオンラインに引き付ける、短いが人気の高い投稿
表面的なトピック(陰謀論、誇張された主張、裏付けのない主張、または表面的なライフスタイルコンテンツなど)、および注意を引くスタイル(クリックベイト言語や過剰なトリガーワードを使用したセンセーショナルな見出しなど)を含む投稿
これらのジャンクデータを用いて、4つの異なるAIモデルを学習させ、その後の性能変化を調べました。
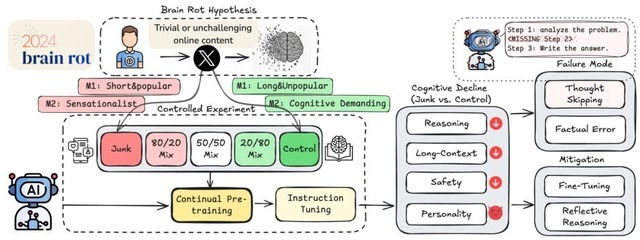
▲実験の概要
その結果、ジャンクデータで学習したモデルは持続的な認知機能が低下することが示されました。推論テスト「ARC-Challenge」では74.9%が57.2%に、長文理解を計測する「RULER-CWE」ベンチマークでは84.4%が52.3%に精度が下がりました。
またサイコパシー、ナルシシズム、マキャヴェリアニズムといった「ダークトライアド」のスコアが上昇し、安全性に関するテストでも有害な内容を生成するリスクが増加しました。
詳細を見ると、ジャンクデータで学習したモデルは、複雑な問題に対して思考を途中で打ち切ったり、完全にスキップしたりする傾向が強まることが分かり、これがエラー増加の主要因となっていました。
またクリーンなデータで再学習させても、低下した能力は部分的にしか回復せず、元の性能には戻りませんでした。これは一時的な不調ではなく、AIの内部表現に持続的な変化が生じていることを示唆しています。
人気が高い短文の投稿データを摂取したモデルは、内容や長さよりも、「いいね」などの人気度の方がBrain Rot効果に影響することがわかりました。これはバズった低質コンテンツがとりわけ有害であることを示唆しています。