


1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、人間の声と区別がつきにくいレベルに迫るリアルな音声を生成できるオープンソソースのText-to-Speech(TTS)「Fish Audio S2 Technical Report」を取り上げます。
Fish Audio S2は、複数話者による複数ターンの対話生成をネイティブにサポートしている点と、自然言語の指示による単語ごとの細かい感情コントロール指定が可能な点が特長です。
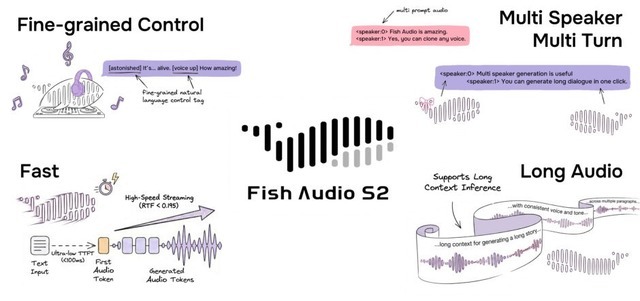
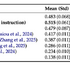
▲Fish Audio S2の4つの主要機能(自然言語タグによる詳細な感情制御、複数話者・複数ターンの対話生成、高速生成、一貫した声質を保つ長尺音声生成)
これまでの多くのAI音声ツールでは、声全体のトーンを「落ち着かせる」「元気にする」といった大まかな調整しかできませんでしたが、Fish Audio S2では、台本の文章の中に直接指示を書き込むことで、単語やフレーズごとの細かい演技指導ができるようになっています。
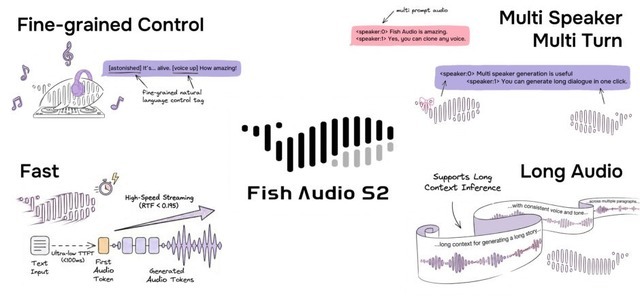
具体的には、角括弧([ ])で囲んで記述するインラインタグです。文の先頭だけでなく、文中の変化させたい特定の単語の直前にタグを配置することで、その後の音声のトーンを正確なタイミングで切り替えることができます。例えば、「[囁き声で] 誰にも聞かせないで。」や「あの時は本当に、[ため息をついて] どうすればいいかわからなかった。」といった具合に指定します。
モデルは約80の言語を理解するため、日本語のスクリプトには日本語でそのままタグを書き込むことができます。
Fish Audio S2は複数話者にも対応しています。テキスト内に話者タグを記述するだけで、複数人が入り乱れる複雑な対話を1回の処理で一発生成できるのも魅力です。個別に音声を生成して後から繋ぎ合わせる手間がなく、会話ならではの自然な間やテンポをそのまま活かした滑らかな掛け合いを実現します。
▲一つのテキスト入力から話者ごとに異なる感情・話し方を持つ多人数対話を一括生成できる
技術的には、Qwen3-4Bをベースとしたアーキテクチャを採用しています。事前学習データのノイズ除去や感情・話者交代の詳細なアノテーションを自動化している点も特徴です。
評価面では、まずAIが作った音声が人間の声と聞き分けられるかを計測するチューリングテスト「Audio Turing Test」において、Fish Audio S2は0.483と、Seed-TTSの0.417やMiniMaxの0.387を上回りました。
さらに、このテストは0.5に近いほど人間か機械か判別不能、つまりより人間らしいことを意味しており、Fish Audio S2(w/ instruction)が唯一それを超える0.515を達成しました。
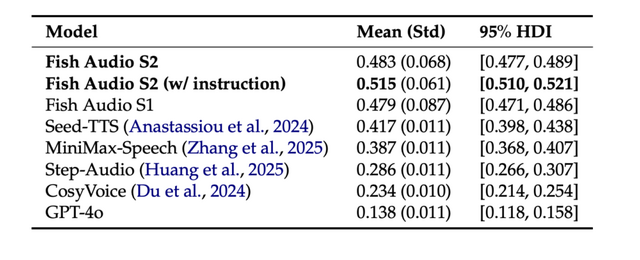
▲Audio Turing Testの結果
また複雑な言語的・韻律的・表現的課題を処理する能力を評価するためベンチマーク「EmergentTTS-Eval」において、Fish Audio S2は総合勝率81.88%と最高値を達成し、全ての比較対象モデルを上回りました。特に言葉以外のニュアンスを評価するパラ言語テストでは91.61%という勝率を誇り、タグを使った細やかな演技指導がいかに正確に声へ反映されているかが証明されています。
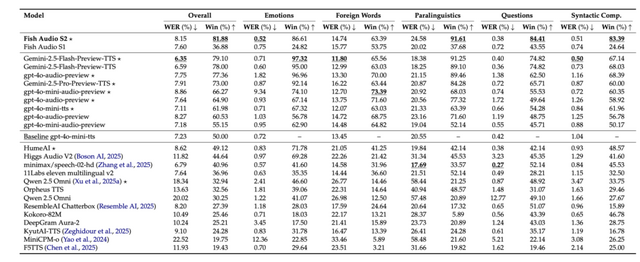
▲EmergentTTS-Evalの結果
そして、実際のシステムとしての処理速度や効率性は、H200 GPUを1台使った環境で音声を生成し始めるまでの待ち時間が約0.1秒(100ミリ秒)です。生成速度は、実際の音声の長さに対して約5分の1(0.195倍)の時間で処理が終わるほどのスピードです。
Fish Audio S2のモデルウェイト、ファインチューニング用のコード、および推論エンジンは、GitHubやHugging Faceを通じて公開されています。これらのモデルは研究および非商用目的であれば無料で利用できますが、商用利用する場合は別途ライセンス契約が必要です。クラウドサービスも用意されており、非商用向けの無料プランに加え、生成した音声の商用利用が認められる有料プランも提供されています。プロジェクトページはこちら。