1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、わずか3秒の参照音声から、自然で表現力豊かな音声を生成できる多言語対応の音声合成(TTS)モデルを提案した論文「Voxtral TTS」を取り上げます。このモデルはフランスのAI企業「Mistral AI」が開発しました。
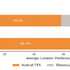
Voxtral TTSは、初めての音声からでも話者の特徴を捉えるゼロショットの音声クローニングにおいて高い性能を発揮します。ネイティブスピーカーによる評価実験では、その自然さと感情表現の豊かさが高く評価され、競合であるElevenLabs Flash v2.5に対して68.4%という高い勝率を記録しました。
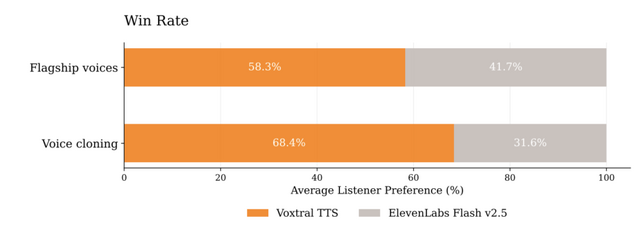
▲Voxtral TTSはElevenLabs Flash v2.5との人間評価において、フラッグシップ音声で58.3%、ゼロショット音声クローニングで68.4%の勝率を達成した
この高い性能を支えているのは、音声を「何を言っているか」(意味的トークン)と「どう聞こえるか」(音響トークン)の2つの要素に分けて処理するハイブリッドアーキテクチャの存在です。
まず、文章の意味情報を文脈に沿って順序立ててしっかり組み立て、何を言っているかを把握し、次にその骨組みに対してどう聞こえるのかの音響情報(声質・抑揚などの情報)を予測して肉付けを行います。この設計により、長い発話にわたる一貫性と、声質や抑揚といった細かな音響的ディテールの両立を実現しています。
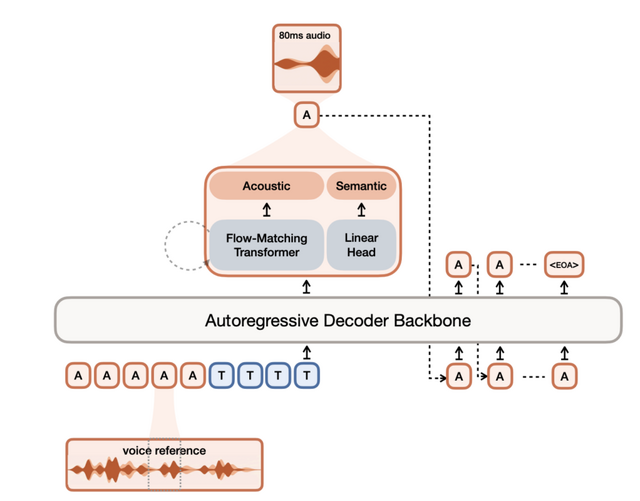
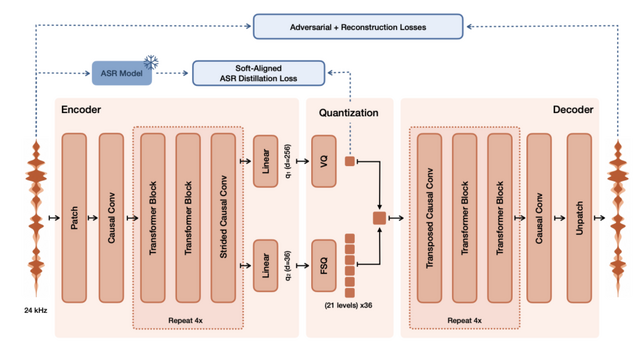
▲Voxtral TTSのアーキテクチャ概要
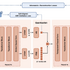
音声を圧縮・復元する部分には「Voxtral Codec」という独自のコーデックを開発し、採用しています。実用面では、NVIDIA H200を1台使った場合、32人が同時に使っても音声が途切れることなくリアルタイムで配信でき、最初の音声が届くまでの待ち時間も1秒未満に収まっています。
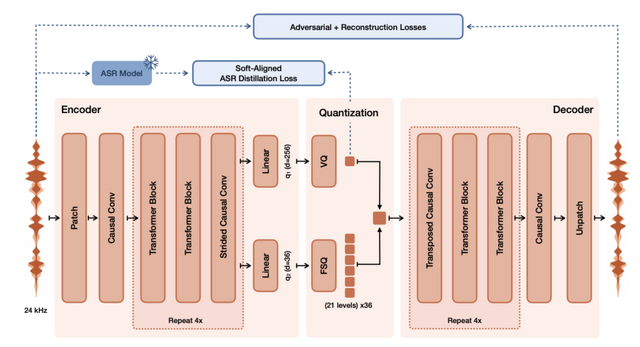
▲Voxtral Codecのアーキテクチャ
現在は、英語、フランス語、スペイン語、ポルトガル語、イタリア語、オランダ語、ドイツ語、ヒンディー語、アラビア語の9言語に対応しています。このモデルの重みは非商用利用で一般公開されています。