パシフィコ横浜にて9月4日から9月6日まで開催されたCEDEC 2019。昨今の半導体事情に注目した「コンピュータ技術最新トレンド」のレポートをお届けします。

このセッションにはテクニカルジャーナリストの後藤弘茂氏が登壇。主にハードウェア的な内容が語れられ、半導体技術やディープラーニングを含めたプロセッサアーキテクチャ、そしてメモリ技術など転換期を迎えた半導体事情が取り上げられました。

■「ムーアの法則」と「デナードスケーリング」の行き詰まり
半導体技術は、ゲームや電子産業を支えているもので進化という観点からワークロードを新しくなっており、ゲーム自体の進化も半導体が支えています。そのなかでアーキテクチャが半導体の制約を受けていることで変化の時を迎えています。

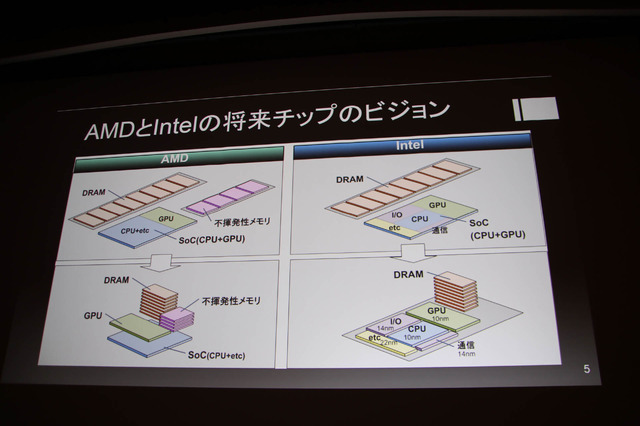
ここでAMDとIntelの将来チップビジョンを紹介。AMDとIntelは、CPUなどユニットごとに分解しDRAMを積み重ねるというビジョンを持っています。それらは現在半導体技術に変動が起きていて色々な影響を与えつつあります。

そのため半導体技術に関してはこれまでと違う流れになりそうで、その原因は「ムーアの法則」と「デナードスケーリング」の行き詰まりであると説明します。この法則を簡単に説明すると、半導体チップのトランジスタ数が一定期間で2倍になること。この法則は経験則と経済則の両面をもっており、チップを製造するコストが変わらないのにトランジスタのコストが半分になります。

デナードスケーリング則は、ムーアの法則に付随する技術則で、世代が進むごとにトランジスタのゲート長と駆動電圧が70%、動作周波数が1.4倍となりますが、消費電力はそのままというもの。そのため2年ごとに2倍の性能を得られ、チップの設計者は簡単に性能を倍にすることが出来ました。これらをフリーランチ(タダ飯)の時代と呼んでいます。

デナードスケーリング則が2000年代に入る頃に電圧が下がらなくなり電力が減らなくなります。逆にチップの電力が上昇。またチップ全体を稼働させると電力が許容範囲を超えてしまうダークシリコン問題が起こります。一方でムーアの法則も2010年代の16/14nmプロセスあたりから顕著になっています。2倍のトランジスタ密度達成に2年以上掛かるようになりウエーハの半導体製造コストが世代毎に上昇。トランジスタのコストも下がりにくくなります。これはタダ飯食いの時代の終わりと呼びます。

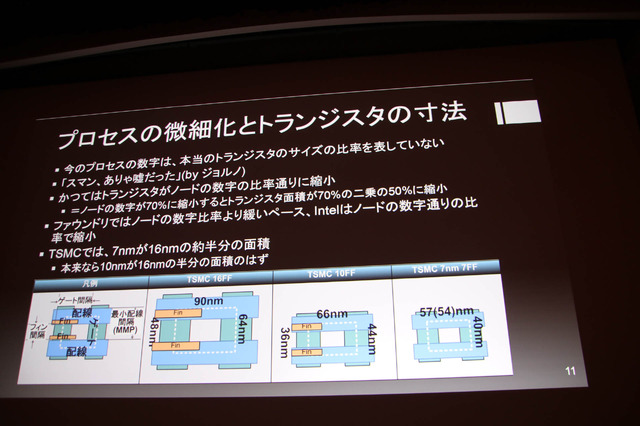
それでも先端プロセス技術は数字上で順調に進行。2019年にはEUV版7nmの製品が本格量産へと移り、5nmプロセスも立ち上げ中です。一方でプロセスの微細化とトランジスタの寸法は、本当のトランジスタのサイズ比率を表していません。また小さいから量産するのに時間が掛かってしまっています。

デナードスケーリングで省電力化が止まったために、電力をONに出来ない部分が増えるダークシリコン問題が発生してしまっています。

またムーアの法則が鈍化した結果、かつて同じコストで小さく出来たものの現在はコストが上昇するか余り下がらなくなっています。このため7nmチップのコストは2倍以上となっており当面はコスト高になっているとのこと。

ムーアの法則が鈍化しデナード則のコスト減もない状態でチップ性能を向上させないと行けないポストムーアの時代がやってきます。性能向上の施策として、回路設計技術の連携としてスタンダードセルを小さくし、マルチチップ化や、プロセッサアーキテクチャの進化が考えられています。

マルチダイ設計とは、小さなチップの組み合わせて大きなチップを作るチップレット化を指し、AMDでは7nm版Zen 2 CPUから始まっています。7nmのZen 2から導入し、CPUは先進的な7nmを、I/O周りは成熟した14nmを採用することで経済的にCPUを開発可能です。


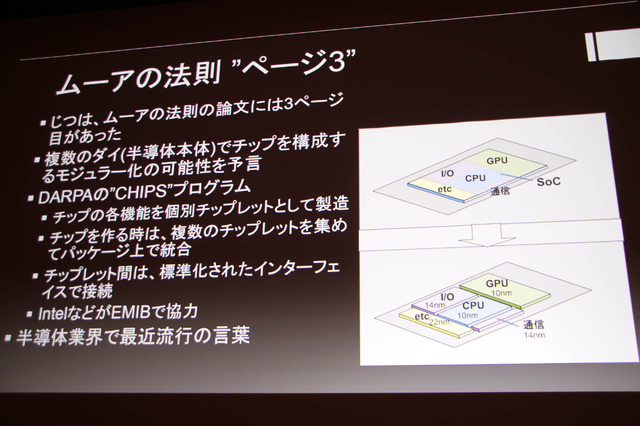
先にムーアの法則が鈍化した話題がありましたが、その論文に3ページがあったことが言及されています。これは、複数ダイでチップを構成するモジュラー化の可能性を予言したものです。
チップレット化の壁は、チップレット同士を接続するインターコネクトが問題で、余計な電力消費とレイテンシやインターコネクトの消費エナジーを抑える必要があります。Intelでは、小さなチップをパッケージに埋め込み低コスト/広帯域/低エナジーのインターコネクトを実現するEMIBがあり、他社にはマネできない切り札であると説明しました。

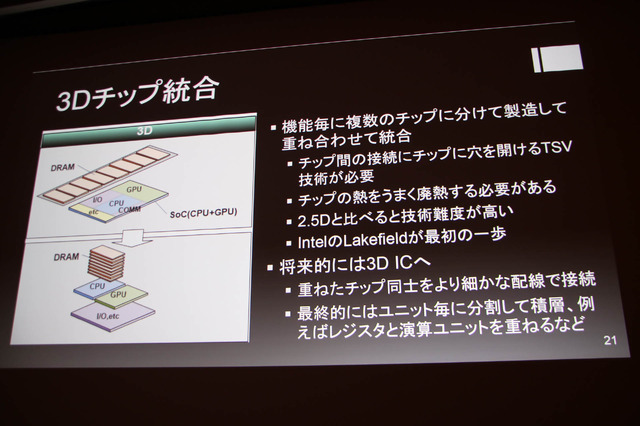
3Dチップ統合は、その名前のとおり機能毎に複数チップを別けて製造し、立体的に重ね合わせて統合するもの。将来的には平面ではなく立体的な3DICへ移行するとみられています。単体のプロセッサを平面的に発展させるのは経済的に見合わなくなってしまっているため、逃げ道はこれしか無くIntelもAMD基本的にはこの流れに沿っているとも解説します。
■ディープラーニングチップなどドメインスペシフィック(分野特化)時代
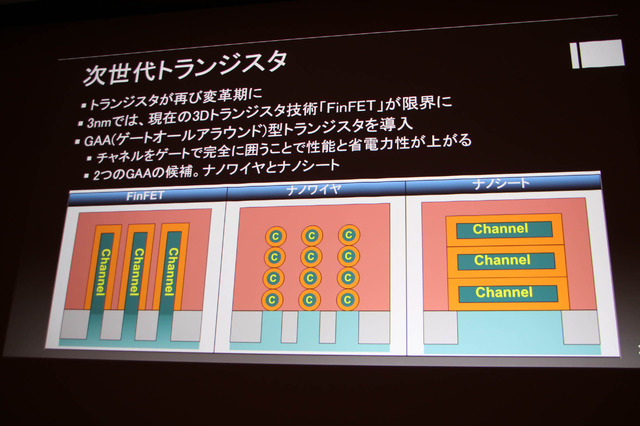
トランジスタは再び変革期に入っており、3nmトランジスタ技術FinFETが限界に到達。GAA型トランジスタを導入し、チャンネルをゲートで完全に加工ことで性能と省電力制が上がります。
ムーアの法則とデナートスケーリング則が鈍化することで自動的に性能が上がる時代が終わり、グスタフスンの法則が効くワークロードは限られてしまっています。またデータフローアーキテクチャのようにこれまでと異なるアプローチを取る必要があります。

これからはドメインスペシフィック(分野特化)の時代です。シングル・マルチスレッド両方の限界が来つつあり微細化プロセスの恩絵が小さいため、行えることはアーキテクチャを特定処理に特化させより小さなタイと省電力で性能を上げるしか無いとのこと。ディープラーニング方面にはドメインスペシフィックがうまく合います。ASICとの違いは汎用性のプロセッサに特定ユニットや命令を追加する方向性です。

汎用CPUの方向性としてはシングルスレッドの性能を高く保ちながら、CPUコア数を増やすことでマルチスレッド性能を向上。Intelの10nm CPUコア「Sunny Cove」は命令並列リソースを大幅に拡張し、ディープラーニング向けベクタ命令「VBBI(Vector Neural Network Instructions)」をサポートします。


また新しいCPU命令「RISC-V」が登場しています。これは米バークレー大学が開発したオープンソースのCPU命令アーキテクチャで、Armと異なりライセンスフリーとなり、誰でもRISC-V互換のCPU開発と製造が可能となります。組み込みMCUから高性能CPUまでカバーし命令の拡張が可能です。

GPUは第2の汎用プロセッサとなっており、出発点はグラフィックスに特化したASICでしたが、現在のGPUは様々な並列タスクに対応出来る汎用性を持っていることです。今後のGPUはドメインスペシフィックな専用機能を追加して性能の向上を狙います。

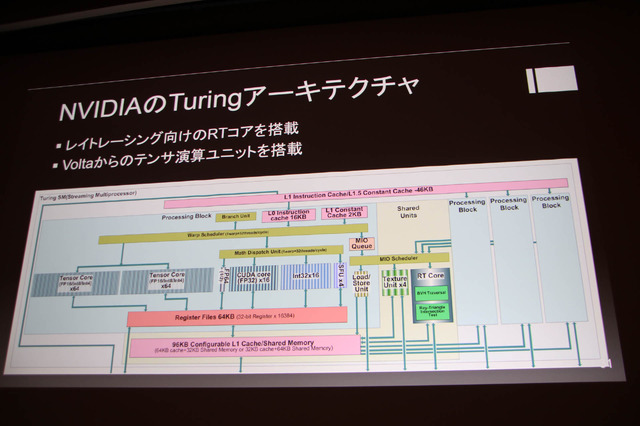
NVIDIAのTuringアーキテクチャはレイトレーシング向けのRTコアとVoltaからテンサ演算ユニットを搭載。NVIDIAの凄いところは一見無駄に見える要素を実装するところにあります。
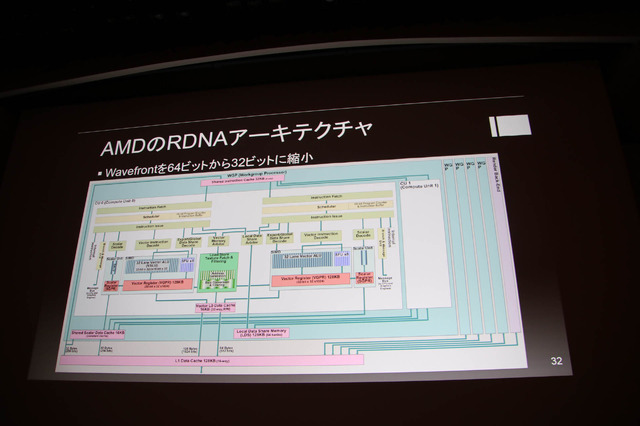
GoogleのクラウドゲーミングプラットフォームStadiaのサーバー側で使われるのはAMDのGPUで、パフォーマンスは10.7TFLOPsの性能を誇りPlayStation 4の5.8倍のグラフィックス性能を持っています。クラウドの利点はサーバー側のプロセッサをアップデートして強化出来る点です。

ゲームに関するディープラーニングの導入はまだ壁があり、GPUのリソースをディープラーニングに割きたくないという事情があります。中期的にはディープラーニングもゲーム分野に浸透し、その範囲はモバイルからサーバーまで増えていくとのこと。

ディープラーニング特化のプロセッサの名前は定まった呼称がありません。ニューラルネットワークは脳神経の仕組みをモデル化したものであり、専用プロセッサの方が効率的です。長期的にニューラルネットワークのワークロードが支配的になると専用プロセッサ搭載が標準になるかもしれません。またディープラーニングチップが続々と登場し、1枚のウエーハそのままチップにする巨大なCerebrasのWafer Scale Engineも現れています。


ディープラーニングには2つのフェイズがあり、トレーニング(学習)とインファレンス(推論)は異なるため、プロセッサの形も変わってきます。またインファレンスを高速化するテクニックはデータ精度を落とすことです。現時点で整数8ビットが主流ですが、1ビットの実装例もあります。加えて高速化を図るには、重要性の低いシナプスやニューロンを削除するプルーニングが行われます(プルーニングは人間の大脳が実際に行っている)。
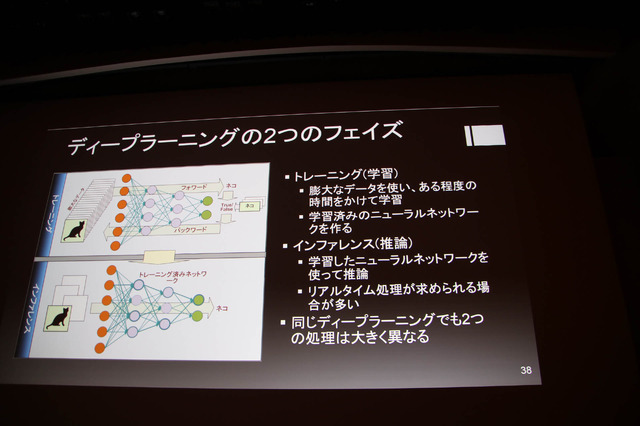

またスマートフォン向けのモバイルSoCでは、CPUとGPUに次ぐ第3のコアとしてディープラーニングプロセッサの搭載が進んでいます。

■DRAMの終焉と半導体の未来
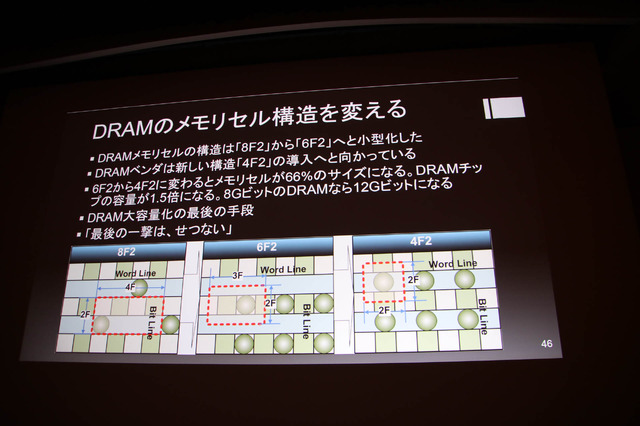
DRAMは新技術に世代交代しつつありGDDR6やLPDDR5、DDR5、HBM3等が挙げられます。この世代交代のペースは緩やかに、HBMは高コストのままなのでゲーム機はGDDR系となっているようです。DRAMが終わる理由としては15nm前後でDRAMのメモリセルを小さくすることが技術的に難しく限界に近づいたためで、あと1回メモリセルの縮小が出来るのみとのこと。


DRAMのメモリセル構造を変えることで8F2から6F2へ、そして4F2化がDRAM大容量最後の手段。DRAMが終わりつつあるので後継のメモリが欲しいものの、不揮発性メモリで代替することは不可能なので、DRAMを補完する方向へと向かっています。メモリインターフェイスに不揮発性メモリを導入し、あたかも数TBのDRAMメモリがあるように扱えることが特徴です。


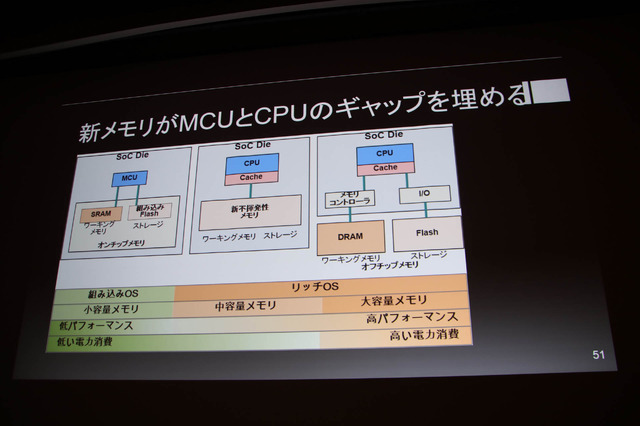
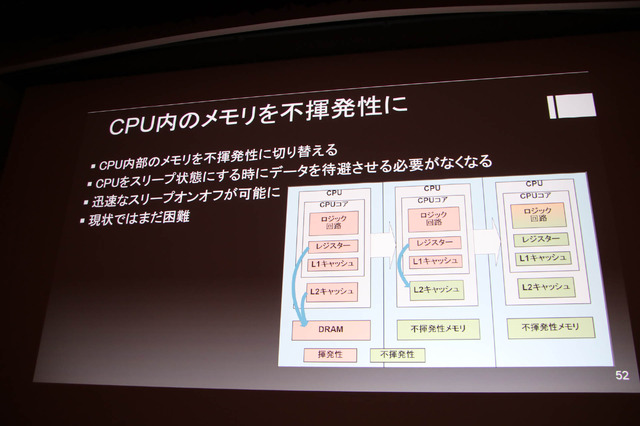
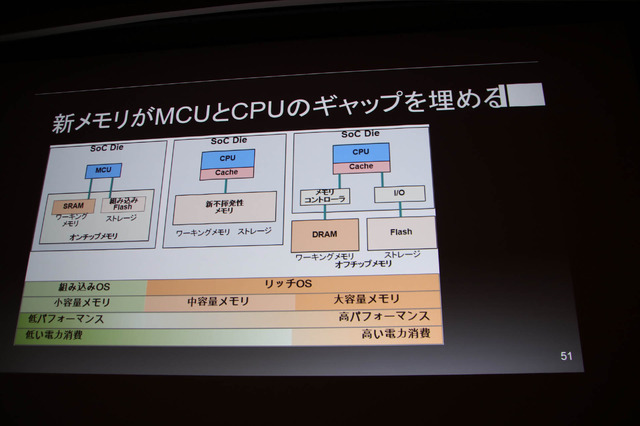
新しい不揮発性メモリが開発中で量産フェイズにあり、CPUなどの倫理回路と相性が良いメモリが多いようです。現在の汎用プロセッサはCPUとMCUの2つに分類され、それらの間にはギャップがあるものの大容量で不揮発性メモリをチップに搭載出来れば間が埋まる。それが実現すればほどほどのパフォーマンスでリッチOSが走り、MCU並の省電力なCPUが可能となります。一方で話題の量子コンピューティングはまだまだ発展段階のようです。

まとめでは、「半導体プロセスの行き詰まり」と「マルチチップ化などの新たなアプローチ」、「プロセッサは分野特化へと向かう」、「ディープラーニングの分野特化が最重要」、「DRAMの終焉と新メモリの開発」、「コンピュータの仕組みの改革」をピックアップしセッションを終えました。