


1週間の気になる生成AI技術・研究をいくつかピックアップして解説する連載「生成AIウィークリー」から、特に興味深いAI技術や研究にスポットライトを当てる生成AIクローズアップ。
今回は、自分のパソコンでどのローカルLLMが快適にかつ賢く動くのか、その答えをコマンド一つで教えてくれるCLIツール「whichllm」の最新版v0.5.10がMITライセンスでリリースされたので取り上げます。
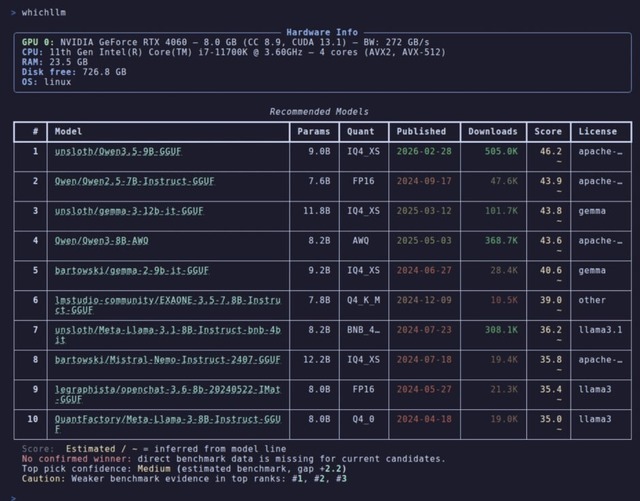
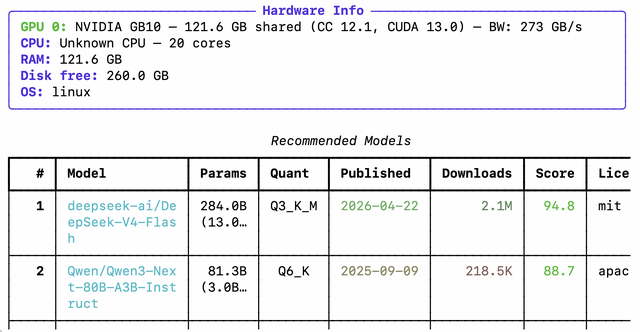
▲whichllmを実行すると、現在のマシンに合った推奨モデルがスコア順でランキング方式に並ぶ
ローカル環境でLLMを動かす際、単にPCのVRAM容量に収まる最大モデルを示すだけのツールは複数あります。しかし、VRAMに収まる多数のモデルの中で、一体どれが最も賢く実用的なのかを判断するのは困難です。
whichllmはその問題を解決します。VRAMに収まる最大モデルで判定するのではなく、収まる複数のモデルの中でどれが一番優秀なのかをランク付けしてくれます。
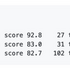
例えば、RTX 4090で実行するとQwen3の32Bのモデルもちゃんと収まるにもかかわらず、27BのQwen3.6が1位に選ばれます。理由は、27Bの方が実ベンチマークで高いスコアを出していて、しかも新しい世代だからです。

▲RTX 4090での実行例。32Bが収まるなかでも、スコアの高い27Bが1位に選ばれている
使い方はターミナルで「whichllm」と打つこと。実行すると、お使いのNVIDIA、AMD、Apple SiliconなどのGPU、あるいはCPUやRAMのスペックを自動的に検出し、HuggingFaceのライブデータ(モデル一覧は6時間、ベンチマークは24時間)からあなたのPCに最適なモデルをランキング形式で提案してくれます。
実際のベンチマーク(LiveBench, Artificial Analysis, Aider, multimodal/vision, Chatbot Arena ELO, Open LLM Leaderboard)、量子化、速度、実行形態、モデル世代などをまとめて 評価し、動く中で相性の良い本当に賢い最適なモデルをランク付けします。
具体的には、ベンチマークの成績を軸に、そのスコアが自己申告ではなく検証済みかで信頼度を測り、また古いモデルが昔の高スコアで現行世代を追い抜かないよう鮮度を考慮します。そこへモデルサイズを加点し、VRAMに収まって高速に動くか、メモリにはみ出して遅くなるかという実行形態や生成スピード、無理な量子化で賢さが損なわれていないかも判断材料にします。さらに提供元が公式組織なら加点・再パッケージ業者なら減点とし、人気度を同点時の決め手として総合スコアを導き出しています。
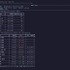
他の使い方として、環境構築の手間なく、選ばれた最適なモデルをダウンロードしてすぐにターミナル上でチャットを始められたり、逆引き機能として指定したモデルに必要なVRAM量と、どのGPUなら動くかを一覧で確認できるなどが可能です。
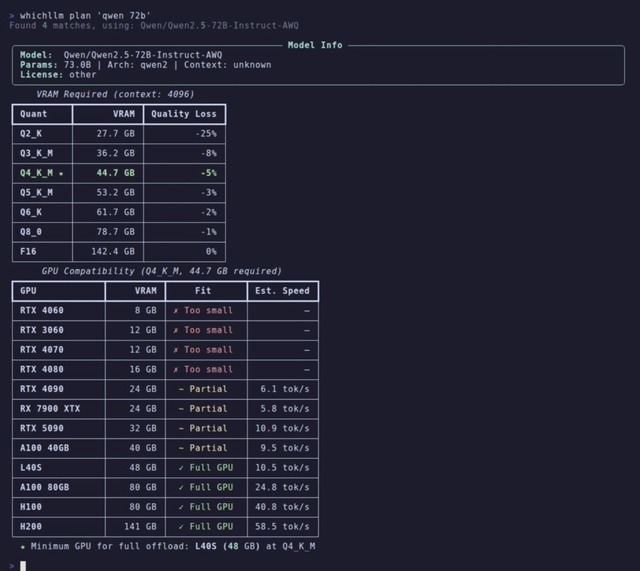
▲指定したモデルに必要なVRAM量と、どのGPUなら動くかを一覧で確認できる逆引きも可能です