パシフィコ横浜ノースの現地とオンラインの両面で8月23日から8月25日まで開催された、ゲーム開発者向け大規模カンファレンスCEDEC2023。AIを活用して、声から本物らしい効果音を生成する「生成系AIを活用した効果音制作手法の研究」のセッションレポートをお届けします。
本セッションには、京都産業大学情報理工学部教授である平井重行氏と、先端情報学研究科大学院2年生である滝沢力氏の2名が登壇しました。このセッションでは、生成AIを利用して効果音を制作する過程の前編と、求めるサウンドを追求する後編の2部で構成されています。


◆声から効果音を生成するってどういうこと?
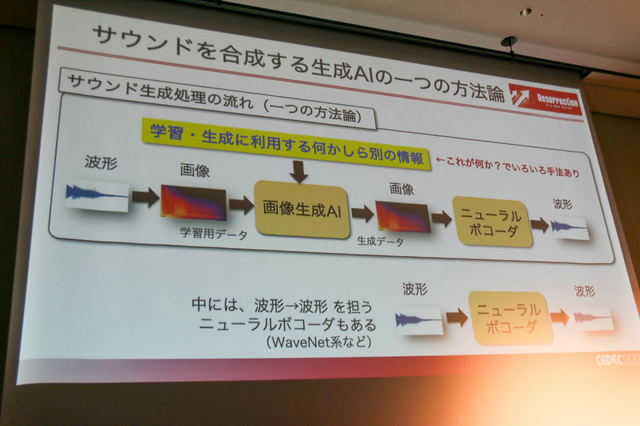
この効果音生成手法の研究セッションでは、サウンドを画像データに変換して画像生成AIを中継することで、リアリティのある効果音を作成する手順が解説されました。サウンドの機械学習を行うオーディオデータは、波形とスペクトル(周波数と振幅)、スペクトログラム(周波数、振幅、時間)、そしてMIDIの4種類あります。波形では情報量が少なく、一方でスペクトルでは時間で変化する音を捉えきれないため、時間の変化も捉えられることを考慮するとスペクトログラムを採用しています。

また、平均的な機械学習で使われているスペクトログラムの中でも、人間の聴覚特性などに合わせられたメルスペクトログラムを採用。これは、周波数特性を考えた時に人間の聴覚が対数軸に沿う音の聞き方をしていることや、人間が極端な高域/低域の音声を発話できないことから選ばれたそうです。
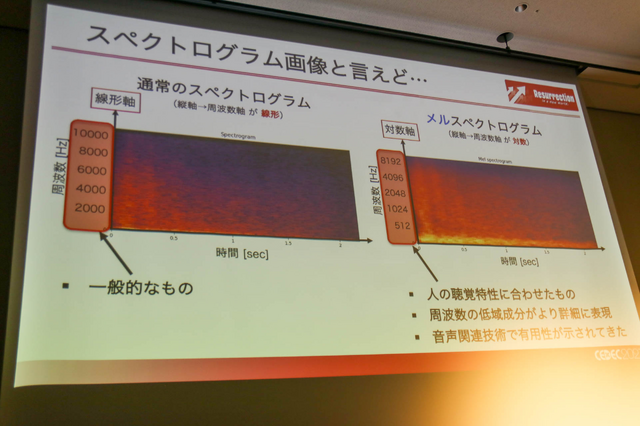
また、メルスペクトログラムは画像データであるために画像生成AIを活用することができます。数多くの画像生成AIがありますが、サウンドの自動生成では深層学習モデル「Transformer」を使用。画像で入力し、画像で出力するため、音として聴くためには出力されたメルスペクトログラム画像を音声に再変換しなければなりません。それにはニューラルネット利用ボコーダー(ボコーダー、ボイスエンコーダーの略)の「iSTFTNet」を使用しています。


ここで音声データ生成の流れをまとめましょう。まず波形として入力した音声データを学習用データとして画像メルスペクトログラムへと変換し、画像生成AIを利用するための情報、画像メルスペクトログラムを生成してニューラルボコーダーで再び波形へと変換するという流れです。
◆音声の変換処理―理想の音を追求するには人間が必要
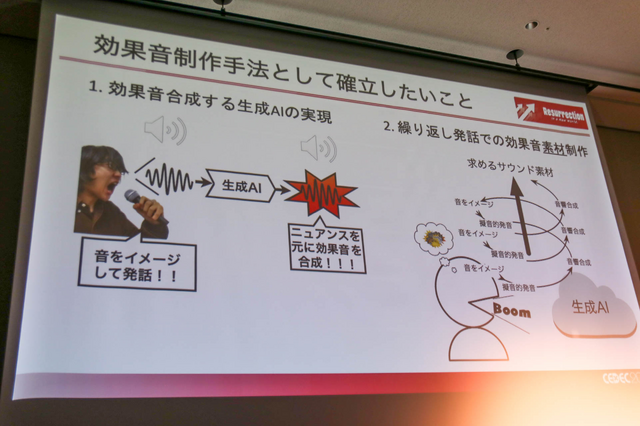
ここでは、擬音音声から効果音(現在は爆発音)を表現した例が披露されました。爆発音を選んだ理由は「(口で)音真似をし易い効果音だから」であり、合成音の韻律やアクセントを制御できるからです。

提案モデルの構成図は先のものと同じ3工程で構成。人間の音声と爆発音の系列変換をモデルが学習することで、音声を爆発音に変える変換モデルを実装しています。学習には正解となる爆発音と、それを真似る擬音語音声を用いたものです。
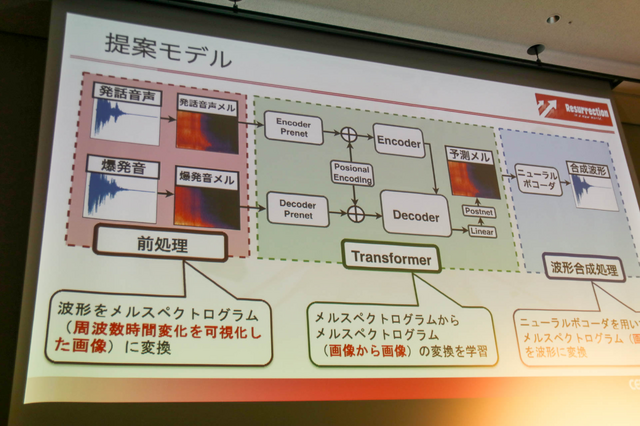
前処理は、振幅に対する当地処理で開始点を決め、波形の終わり1/10でフェードアウト処理を実施。メルスペクトログラム画像の縦軸は80次元(少端数分解能が80)に、横軸を時間として変換します。

Transformerでは、スペクトログラムからスペクトログラムの変換を学習し、Encoder/Decoder Prenetにおいて周波数軸の次元数を80次元から256次元へ拡張。モデルの入力として、人間が喋る擬音語音声をEncoderに、爆発音をDecoderに入力します。
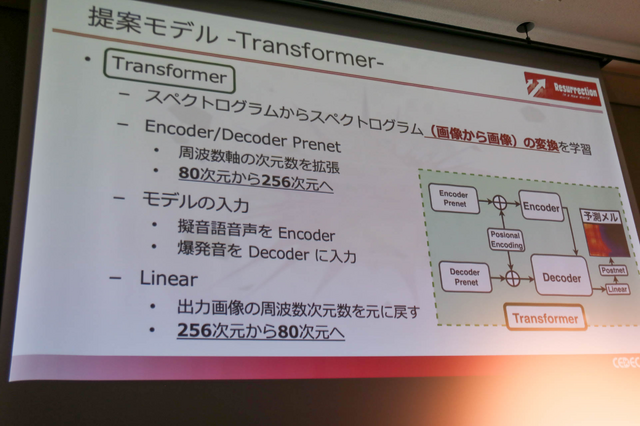
そうした後に出力画像の周波数次元数を256次元から80次元へ変換し、元の爆発音からの損失を計算することで学習。波形合成処理ではニューラルボコーダーを用いてTransformerの予測画像を波形データに戻します。

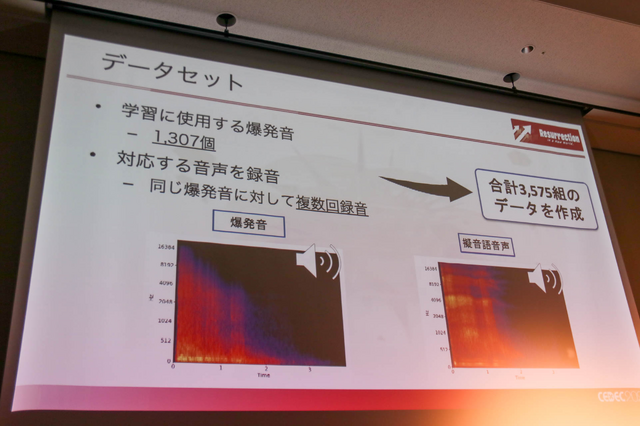
学習で使う爆発音は、フリーや有償に問わないデータセットから1307個収集し、一つの爆発音に対して複数回録音して、合計3575組のデータを作成しています(ここで爆発音と擬音語音声を披露された)。ここでは、入力音声と合成処理を紹介し、擬音語音声に限りなく近い合成結果が得られました(もちろん、上手くいかなかったデータも多く存在する)。
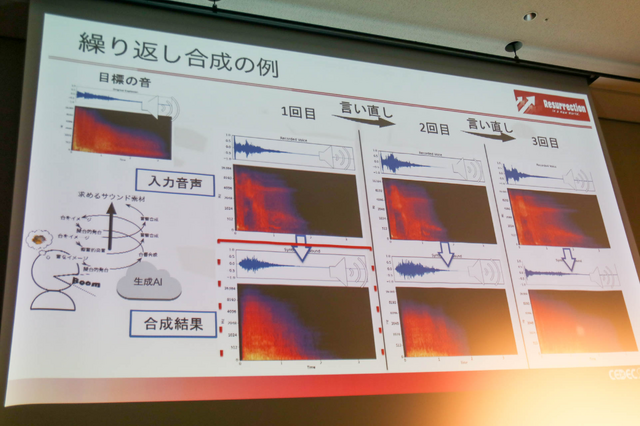
この精度を高めていく過程はHuman-In-The-Loop(HITL)と呼び、生成の結果から人間が良し悪しを判断し、更にイメージに近い発音を繰り返すことで、求めるサウンド素材を突き詰めていくというもの。サイクルとしては、音を想像→ニュアンスを含めて発音→モデルに入力して合成→臨んだ音かを判断しNOであれば初めに戻るという順序で高めます。
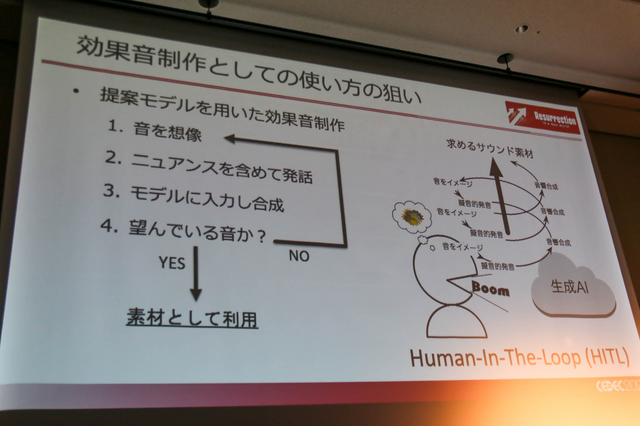
こうして精度を高めて披露された音声変換は、まさにイメージ通りの爆発音が得られていました。セッションを聞いている限りでは、今すぐにでも本番で使えそうな精度であることを感じますが、課題もまだ多いそうです。
それらは「擬音的発音データ」のデータセットがこの世に存在しないことから自ら録音してデータセットをつくり出す必要があることや、他の効果音でも合成を試すにはデータセットを1からつくる必要があること、そしてデザイン手法しての検証が足りていないことなどです。特に爆発音以外のビーム音や魔法の音などを追求するには、それに応じた擬音語発音を新たに収録しなければなりません。
加えて、この研究は大学の研究室で行われているものなので、実際の制作現場で試行錯誤することや協力関係を結ぶことなども課題です。メルスペクトログラムは主に音声を主体とし、効果音はより広帯域の周波数であるために、高域が圧縮されてしまうメル周波数より普通のスペクトログラムを使うべきでは? という疑問もあります。これらの課題を述べてセッションは終了しました。

以上がセッションの内容でした。擬音的発音から実際に爆発音がつくり出される過程はとても面白く、これが実用化されればより楽しげで飽きがきにくい独特なサウンドエフェクトをつくり出せそうです。しかし、音声データの蓄積が難しそうなデータセットの存在や、メルスペクトログラムで進むべきなのか? など疑問点や課題が多いことも語られたため、「誰もが使える」段階での実用化にはまだまだ時間が必要とも思えました。画像や文章だけでなく、サウンド分野の生成AIにも日々注目しておくのが良いかもしれません。