Google DeepMindが、ノートPCでの利用を想定したマルチモーダルAIモデル「Gemma 4 12B」を公開しました。Hugging FaceやKaggleからダウンロードでき、Apache 2.0ライセンスで自由に利用できます。
Gemma 4 12Bは、スマホ等でも動くエッジ向けの「E4B」と、高性能な「26B Mixture of Experts(MoE)」の中間に位置する中規模モデル。
16GBのVRAMまたは統合メモリを搭載した一般的なノートPCで動き、画像の分析や音声の書き起こしから要約など、テキスト・音声・ビジョンを統合して扱う強力なマルチモーダル・エージェント機能を一般的なハードウェアでローカル実行できます。
技術的な特筆性は、エンコーダーフリーのユニファイドアーキテクチャを採用したこと。従来のマルチモーダルモデルでは、画像や音声を処理するために個別のエンコーダーを使用していましたが、Gemma 4 12Bでは廃止。
視覚入力は軽量な埋め込みモジュールに置き換えられ、音声入力はGemmaシリーズで初めて、生の音声信号をテキストトークンと同じ次元空間に直接投影するネイティブ方式を採用しています。これにより、遅延の削減とメモリ使用量の低減を同時に実現しています。
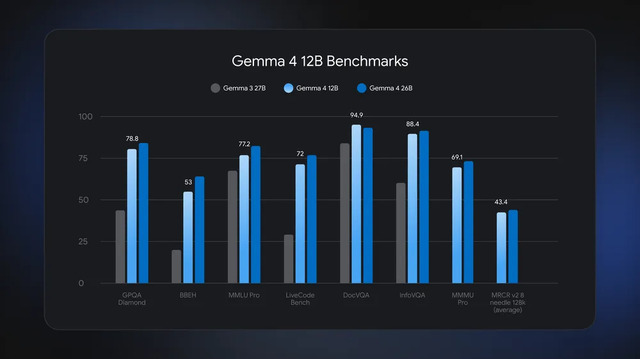
DeepMindいわく、推論性能は26B MoEモデルに迫る水準を達成。複数ステップにわたる推論やエージェントワークフローにも対応します。さらに、レイテンシ削減を目的とした「Multi-Token Prediction(MTP)ドラフター」も搭載されています。
ライセンスはApache 2.0で公開されており、開発者エコシステム全体での利用が可能です。ウェイトはHugging FaceおよびKaggleから直接ダウンロードでき、Hugging Face Transformers・llama.cpp・MLX・SGLang・vLLMなど主要な推論フレームワークに対応しています。ファインチューニングにはUnslothの利用も可能です。
エージェント開発を支援する公式「Gemma Skills Repository」も同時に公開されました。これはGemmaモデルを活用したエージェント構築に特化したスキルライブラリです。本番環境への展開にはGoogle Cloudを通じて、Gemini Enterprise Agent Platform Model Garden・Cloud Run・GKEなどのオプションが用意されています。
Gemmaシリーズはこれまでに累計1億5000万ダウンロードを突破しており、装着型ロボットアームから企業向けAIセキュリティまで、幅広い用途での活用が報告されています。Google DeepMindは今後もオープンなAI開発の推進を続ける方針です。